The AI Solopreneur Tech Stack Decision Nobody Talks About: Single-Cloud Risk
Your AI solopreneur tech stack has a hidden fragility point. What Railway's 8-hour GCP outage teaches solo founders about single-cloud risk and resilience.
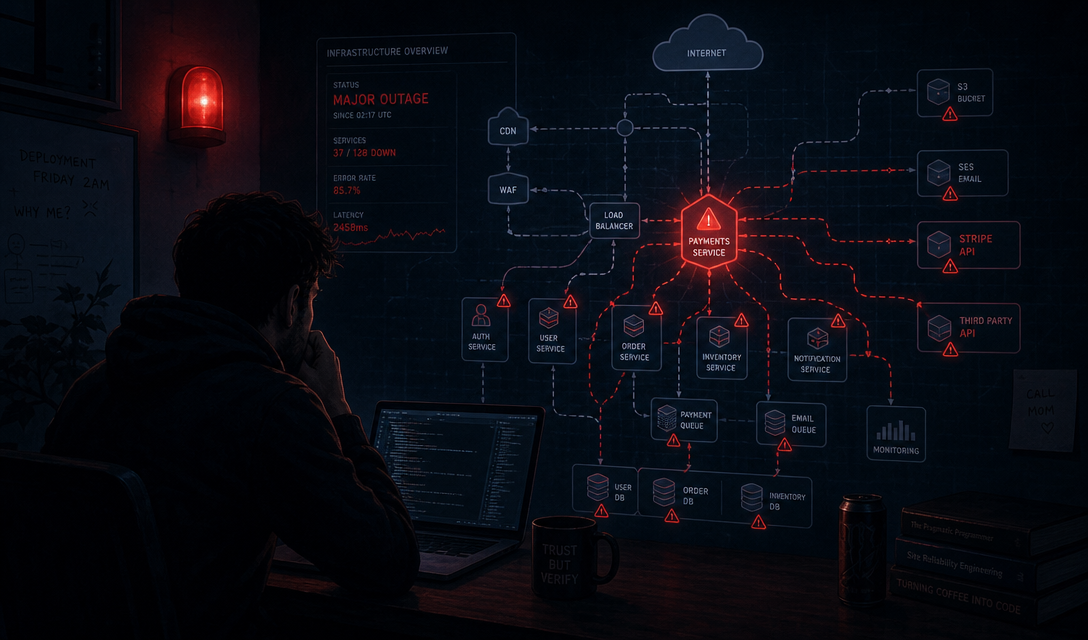
On May 19, 2026 — the same day as Google I/O — Railway's entire production platform went down for eight hours. API, dashboard, every customer workload. Not because of a bad deployment or a scaling failure. Because Google Cloud's automated system flagged Railway's account and suspended it. No human reviewed it. No warning. Just: gone.
Railway's founder called it "gobsmacking." I'd call it a masterclass in the infrastructure fragility that almost every solo founder ignores when building out their AI solopreneur tech stack.
What Actually Happened (and Why It Should Concern You)
Here's the cascade: Google Cloud's automated account suspension system incorrectly flagged Railway's production GCP account. That took down their API and dashboard immediately. But it also took down their AWS workloads — because their edge proxies routing traffic were hosted on GCP. Even infrastructure on a different cloud became unreachable.
The outage lasted 8 hours. Resolution required direct escalation to a GCP account manager. And the blast radius kept expanding: GitHub rate-limited Railway's OAuth and webhook integrations because of the high call volume during cache recovery.
Railway is not a tiny side project. They're a real developer cloud platform with paying enterprise customers. And one automated system decision — with no human override, no warning, no appeals process — took them completely dark.
Full restoration: 07:58 UTC on May 20.
The Hidden Fragility in Most AI Stacks
When founders think about their AI solopreneur tech stack, they're usually optimizing for the fun stuff: which LLM to call, how to structure prompts, whether to use LangChain or raw API calls. Infrastructure decisions get made fast and rarely revisited.
The typical solo AI stack looks something like this:
- Compute: Vercel or Railway (hosted on GCP or AWS)
- Database: PlanetScale, Supabase, or Neon (all cloud-dependent)
- AI inference: OpenAI or Anthropic APIs
- Auth: Clerk or Auth0
- Payments: Stripe
Every single layer has a dependency on a company that can, in theory, suspend your access. Not maliciously — but automatically, at scale, because their fraud detection or abuse system made a decision.
The Railway incident exposed something specific: your backup cloud isn't actually a backup if your routing layer lives on the primary cloud. This is the architectural assumption that collapsed. The edge proxies — the layer that tells traffic where to go — were the single point of failure, even though the compute behind them was on a different provider.
Why This Risk Is Higher for Solo Founders
Enterprise customers have account managers, dedicated support lines, and contractual SLAs. When Railway needed to restore service, they had to engage a GCP account manager directly. That worked — eventually.
As a solo founder, you probably don't have that relationship. You're on a free tier, a self-serve plan, or a small subscription. If an automated system flags your account, you're waiting in a support queue. And if you've built your entire product on a single cloud provider's infrastructure — with no multi-cloud routing, no fallback endpoints, no data export strategy — you're not just down. You're stuck.
The irony is that AI-native products are more vulnerable here, not less. LLM-heavy applications often require:
- API keys and credentials stored in provider-managed secret systems
- Inference endpoints that go through a specific cloud's routing
- Fine-tuned models hosted on a single provider
- Vector stores or embeddings tied to proprietary infrastructure
Each of these is a suspension point. Not just the compute layer.
What a More Resilient Stack Looks Like
This isn't an argument for complexity. Over-engineering infrastructure as a solo founder is its own kind of failure mode — you end up maintaining a Kubernetes cluster instead of building the product. The goal is asymmetric resilience: small architectural choices that dramatically reduce your blast radius.
Separate your routing from your compute. If you use GCP for your backend, consider a CDN or edge layer (Cloudflare, Fastly) that doesn't depend on GCP. This is exactly what Railway's incident revealed — the GCP-hosted edge proxies were the critical dependency, not the GCP compute itself.
Use provider-agnostic secret management. Storing secrets in Google Secret Manager or AWS Secrets Manager is convenient until your account is suspended. A tool like Infisical or Doppler that sits outside your cloud provider adds one layer of independence.
Pick LLM providers that have multiple access paths. OpenAI and Anthropic both have direct API access. If you route all your inference through a single cloud provider's hosted version of a model, you're adding a dependency. Going direct to the API is usually simpler and more resilient.
Have a manual recovery path documented. Not automated failover — just a document that says: if X goes down, here's where our data is, here's how we re-deploy, here's the backup endpoint. When your routing cache is gone and you're running on adrenaline at 2 AM, a clear checklist is worth more than a complex automated recovery system you've never tested.
Know your account contacts. This sounds obvious, but many founders don't set up a business account with a dedicated support escalation path until after they need one. If you're paying meaningfully for infrastructure, it's worth a 30-minute call to understand what your support options actually are.
The Real Lesson From the Railway Incident
Railway was transparent about what happened, published a detailed post-mortem, and restored service in under 8 hours. That's actually pretty good crisis response. But they also called the root cause clearly: an automated system made a wrong decision that a human wouldn't have made, and the recovery depended entirely on finding the right human at Google to override it.
For solo founders, the calculus is different. You don't have a team managing the incident. You don't have a PR team writing the post-mortem. You have you — possibly in the middle of another task, possibly asleep — when the alert fires.
The question isn't whether automated systems will make wrong decisions. They will. The question is: how many of those wrong decisions are single points of failure for your business?
A good AI solopreneur tech stack isn't just optimized for speed and cost. It's designed so that when one provider has a bad day, your customers don't have to share it.
Railway published a full incident report at blog.railway.com. Worth reading if you run anything production-critical on a cloud platform.
Dela detta

Skrivet av Feng Liu
shenjian8628@gmail.com