Del 2: Bygg din första AI-agent: En praktisk guide med LangChain
De flesta tutorials om AI-agenter skippar de stökiga detaljerna. Här visar jag hur jag byggde en fungerande agent med LangChain, tRPC och PostgreSQL – inklusive misstagen jag gjorde längs vägen.
Hypen kring AI-agenter är verklig. Alla pratar om autonoma system som kan tänka, planera och utföra uppgifter. Men här är grejen ingen berättar för dig: de flesta tutorials visar bara "the happy path" och hoppar över delarna där saker går sönder.
Förra veckan spenderade jag två dagar på att bygga en AI-agent från grunden. Inte ett leksaksexempel – utan en riktig en som hanterar en bloggplattform, skapar användare, skriver inlägg och faktiskt fungerar. Jag tänker visa exakt hur jag gjorde det, inklusive de delar som inte fungerade vid första försöket.
Hela koden: github.com/giftedunicorn/my-ai-agent
Vad vi faktiskt bygger
Glöm de abstrakta exemplen. Vi bygger en agent som:
- Skapar och hanterar användare i en PostgreSQL-databas
- Genererar blogginlägg på begäran
- Svarar i konversationsform samtidigt som den använder verktyg
- Behåller konversationshistorik
- Faktiskt deployas (inte bara localhost-demos)
Stacken: Next.js, tRPC, Drizzle ORM, LangChain och Googles Gemini. Inte för att det är trendigt – utan för att det är typsäkert, snabbt och faktiskt fungerar i produktion.
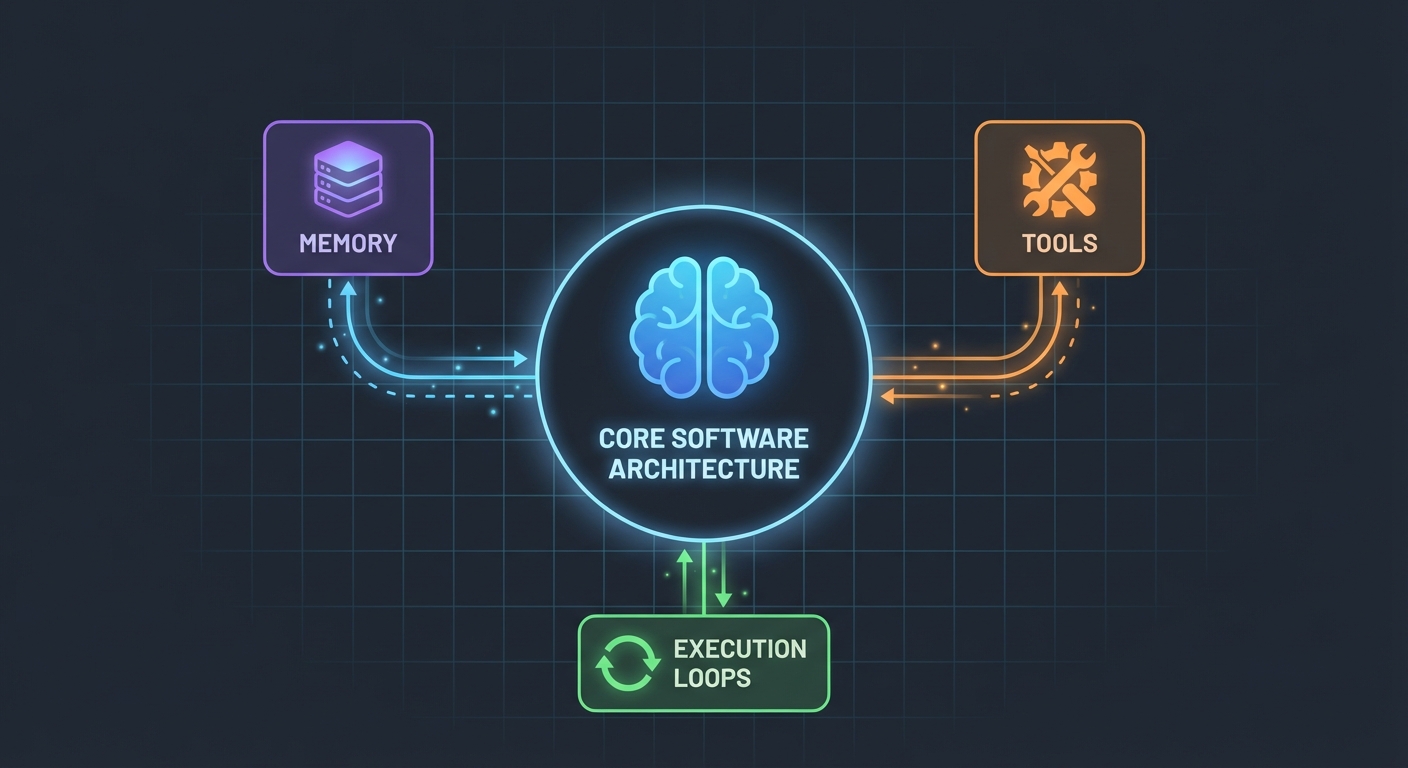
Arkitekturen (Enklare än du tror)
Här är vad som förvånade mig: AI-agenter är inte så komplicerade. I grund och botten är de bara:
- En LLM som kan anropa funktioner
- En uppsättning verktyg som LLM:en kan använda
- En loop som exekverar dessa verktyg
- Minne för att behålla kontext
Det är allt. Komplexiteten ligger i att få dessa delar att fungera pålitligt tillsammans.
Databasschemat
Först, grunden. Vi behöver tabeller för användare, inlägg och meddelanden:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Inget märkvärdigt. Bara ren, relationell data med PostgreSQL. Message-tabellen lagrar konversationshistorik – vilket är avgörande för att behålla kontexten mellan förfrågningar.
Bygga verktygen (Där magin sker)
Det är här de flesta tutorials blir luddiga. "Skapa bara några verktyg," säger de. Låt mig visa hur det faktiskt ser ut.
Verktyg är funktioner din AI kan anropa. Med LangChains DynamicStructuredTool definierar du:
- Vad verktyget gör (beskrivning)
- Vilken input det behöver (schema med Zod)
- Vad det faktiskt exekverar (funktion)
Här är verktyget för att skapa användare:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Beskrivningen är viktigare än du tror. LLM:en använder den för att avgöra när detta verktyg ska anropas. Var specifik med när det ska användas.
Returvärdet? Det är vad LLM:en ser. Jag returnerar strukturerad text med alla relevanta detaljer – ID:n, namn, bekräftelse. Detta hjälper LLM:en att ge bättre svar till användarna.
Agenten: Att sätta ihop allt
Här blir det intressant. Det nya LangChain API:et (v1.2+) förenklade allt:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
Det är allt. Ingen ChatPromptTemplate, ingen AgentExecutor, inga komplexa kedjor. Bara createAgent och invoke.
System-prompten (Din agents personlighet)
Det är här du lär din agent hur den ska bete sig:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Jag lärde mig detta den hårda vägen: var tydlig. Tala om för agenten exakt vad den ska göra, hur den ska svara och vilka detaljer den ska inkludera. Vaga prompter leder till vagt beteende.
Hantera konversationshistorik
De flesta exempel hoppar över detta, men det är kritiskt för en bra användarupplevelse. Så här hanterar jag det:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Enkelt, men effektivt. Agenten kommer nu ihåg de senaste 10 utbytena. Tillräckligt för kontext, men inte så mycket att den blir förvirrad eller dyr i drift.
De stökiga delarna (Det som faktiskt gick sönder)
Cirkulära beroenden: Mitt första försök misslyckades eftersom agent.ts importerade appRouter, som importerade agentRouter, vilket skapade ett cirkulärt beroende. Lösningen? Skapa en temporär router inline med bara de routrar du behöver för verktygen.
Extrahering av verktygssvar: LangChains svarsformat ändrades i v1.2. Resultatet ligger nu i result.messages[result.messages.length - 1].content, inte result.output. Det tog mig en timme att lista ut.
Typsäkerhet: Verktygets func-parameter behöver explicit typning. Du kan inte bara destrukturera – du måste casta input först. TypeScript kommer inte att hjälpa dig här.
Sätt upp din egen
Här är vad du faktiskt behöver:
- Installera beroenden:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Miljövariabler:
POSTGRES_URL="your-database-url" # Testa Vercel Postgres, Supabase eller lokal PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Hämta från https://aistudio.google.com/app/apikey
- Databas-setup:
pnpm db:push # Skapar tabeller från schemat
- Börja bygga:
- Definiera ditt databasschema
- Skapa tRPC-procedurer för CRUD-operationer
- Bygg LangChain-verktyg som wrappar dessa procedurer
- Skapa agenten med dina verktyg
- Koppla ihop det med din frontend
Vad jag skulle gjort annorlunda
Om jag började om imorgon:
Börja med färre verktyg. Jag byggde 7 verktyg initialt. Håll dig till 3-4 kärnverktyg först. Få dem att fungera perfekt, expandera sedan.
Testa verktyg oberoende. Vänta inte tills agenten är byggd för att testa dina verktyg. Anropa dem direkt med testdata först.
Övervaka verktygsanvändning. Jag lade till loggning för att se vilka verktyg agenten anropar och varför. Detta avslöjade att mina verktygsbeskrivningar behövde förbättras.
Använd streaming. Just nu väntar användarna på det fullständiga svaret. Streaming skulle få det att kännas snabbare, även om det tar lika lång tid.
Verklighetskollen
Att bygga AI-agenter är inte magi, men det är inte trivialt heller. Du kommer att spendera mer tid på:
- Verktygsdesign (vad ska varje verktyg göra?)
- Prompt engineering (hur får jag agenten att bete sig korrekt?)
- Felhantering (vad händer om databasen är nere? vad händer om LLM:en hallucinerar?)
- Typsäkerhet (att göra TypeScript nöjd med dynamiska LLM-svar)
Än på själva AI-delen.
Testa själv
Koden för den här guiden är på riktigt – jag byggde den medan jag skrev detta. Du kan:
- Testa den med: "create 3 mock users"
- Prova: "create 2 blog posts for user 1"
- Fråga: "how many users do we have?"
Agenten hanterar allt detta genom att besluta vilka verktyg som ska anropas, exekvera dem och svara i konversationsform.
Vad händer härnäst
Detta är bara grunden. Härifrån kan du:
- Lägga till autentisering (vem får skapa vad?)
- Implementera strömmande svar (streaming)
- Lägga till mer komplexa verktyg (sök, analys, integrationer)
- Bygga en feedback-loop (lyckades verktygsanropet?)
- Lägga till rate limiting (låt inte användare skapa 10 000 inlägg)
Men börja enkelt. Få ett verktyg att fungera bra innan du lägger till tio mediokra.
Det bästa? När du väl förstår detta mönster – verktyg + LLM + minne – kan du bygga agenter för vad som helst. Databashantering, kundsupport, innehållsgenerering, vad som helst.
Den svåra delen är inte koden. Det är att designa verktyg som faktiskt löser riktiga problem.
Resurser:
- Full källkod: github.com/giftedunicorn/my-ai-agent
- Byggt med Create T3 Turbo
- LangChain Docs: js.langchain.com
- Hämta Gemini API-nyckel: aistudio.google.com
Dela detta

Skrivet av Feng Liu
shenjian8628@gmail.com