第2回:LangChainでつくる初めてのAIエージェント:実践ガイド
多くのAIエージェントのチュートリアルは、一番「泥臭い」部分を飛ばしがちです。LangChain、tRPC、PostgreSQLを使って実際に動くエージェントを構築したプロセスを、途中の失敗や試行錯誤も含めて包み隠さず共有します。
AIエージェントへの熱狂(ハイプ)は本物です。誰もが、思考し、計画し、タスクを実行できる自律型システムについて語っています。しかし、誰も教えてくれないことがあります。ほとんどのチュートリアルは「ハッピーパス(理想的な成功ルート)」しか見せず、物事が壊れる部分を飛ばしているのです。
先週、私は2日間かけてゼロからAIエージェントを構築しました。おもちゃのようなサンプルではなく、ブログプラットフォームを管理し、ユーザーを作成し、記事を書き、実際に動作する本物のエージェントです。今回は、私がどのようにそれを実現したのか、そして初回にうまくいかなかった部分も含めて、包み隠さずお見せします。
完全なコード: github.com/giftedunicorn/my-ai-agent
実際に構築するもの
抽象的な例は忘れましょう。今回構築するのは、以下のようなエージェントです:
- PostgreSQLデータベースでユーザーを作成・管理する
- リクエストに応じてブログ記事を生成する
- ツールを使用しながら会話形式で応答する
- 会話の履歴を保持する
- 実際にデプロイ可能(単なるローカルホストのデモではない)
技術スタックは、Next.js、tRPC、Drizzle ORM、LangChain、そして GoogleのGemini です。これらを選んだのは流行っているからではありません。型安全で、高速で、本番環境で実際に使えるからです。
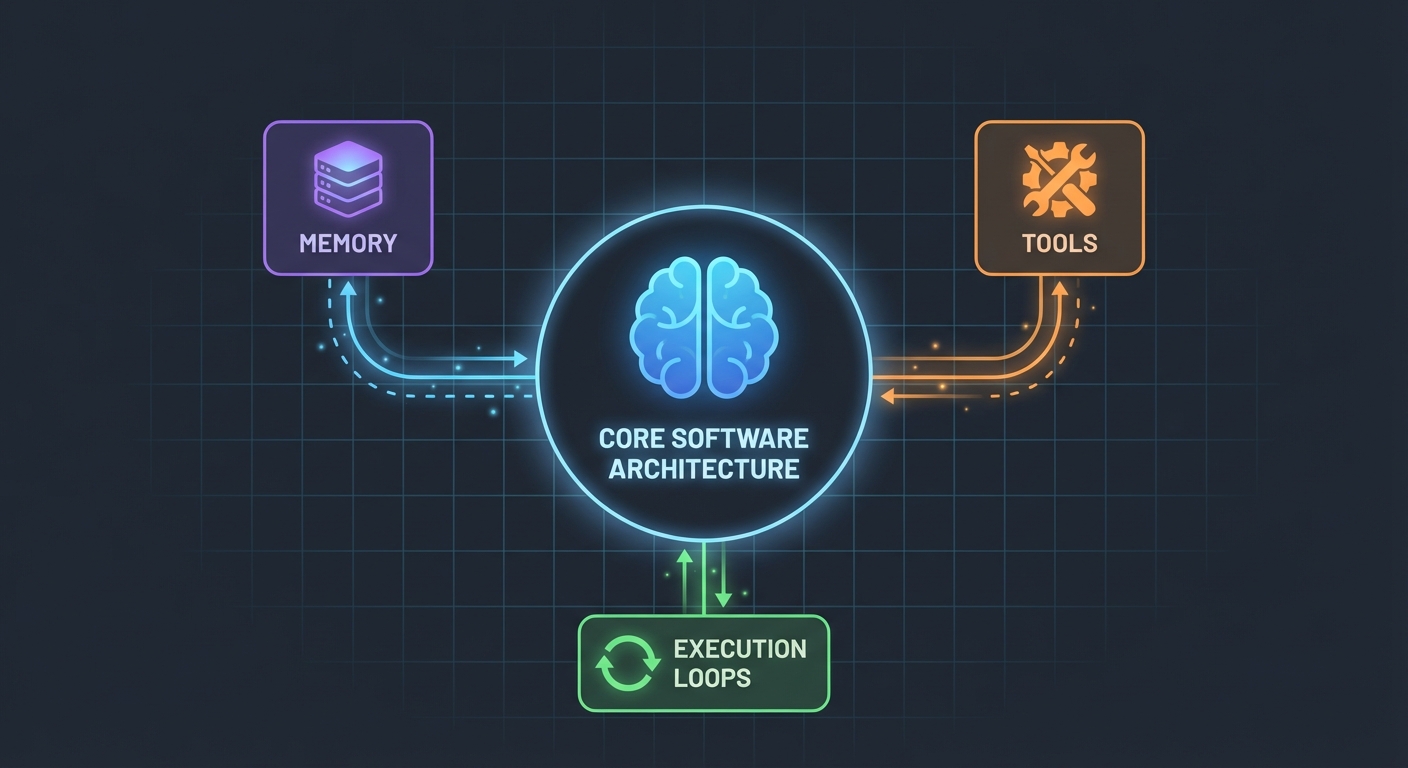
アーキテクチャ(思ったよりシンプルです)
驚いたことに、AIエージェントの仕組みはそれほど複雑ではありません。核心部分は以下の通りです:
- 関数を呼び出せるLLM
- LLMが使用できるツールセット
- それらのツールを実行するループ
- コンテキストを維持するためのメモリ
これだけです。複雑さは、これらのピースを確実に連携させるところにあります。
データベーススキーマ
まずは基礎から。ユーザー、記事、メッセージのためのテーブルが必要です:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
特別なことは何もありません。PostgreSQLを使ったクリーンなリレーショナルデータです。Message テーブルは会話履歴を保存します。これはリクエスト間のコンテキストを維持するために不可欠です。
ツールの構築(魔法が起きる場所)
ここが、多くのチュートリアルで曖昧にされている部分です。「とりあえずツールを作ればいい」と言われますが、実際にはどのようなものなのでしょうか。
ツールとは、AIが呼び出すことができる関数のことです。LangChainの DynamicStructuredTool を使って、以下を定義します:
- ツールが何をするか(説明文/description)
- どのような入力が必要か(Zod を使ったスキーマ)
- 実際に何を実行するか(関数)
以下は、ユーザーを作成するためのツールです:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
説明文(description)は、あなたが思う以上に重要です。LLMはこの説明文を見て、いつこのツールを呼び出すべきかを判断します。いつ使うべきか、具体的に記述してください。
戻り値についてはどうでしょうか? それがLLMが見る内容になります。私は、ID、名前、確認メッセージなど、関連するすべての詳細を含む構造化されたテキストを返しています。これにより、LLMはユーザーに対してより適切な応答を返すことができます。
エージェント:すべてを組み合わせる
ここからが面白いところです。新しいLangChain API (v1.2以降) によって、すべてがシンプルになりました:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
これだけです。ChatPromptTemplate も AgentExecutor も、複雑なチェーンも必要ありません。ただ createAgent して invoke するだけです。
システムプロンプト(エージェントの人格)
ここで、エージェントにどのように振る舞うべきかを教え込みます:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
私は苦労してこれを学びました:明確にすることです。エージェントに何をすべきか、どう応答すべきか、どの詳細を含めるべきかを正確に伝えてください。曖昧なプロンプトは、曖昧な挙動につながります。
会話履歴の処理
多くのサンプルコードではここが省略されていますが、優れたユーザー体験には不可欠です。私は以下のように処理しています:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
シンプルですが効果的です。これでエージェントは過去10回のやり取りを記憶します。文脈を理解するには十分ですが、混乱したりコストがかさむほど多くはありません。
泥臭い部分(実際に壊れた箇所)
循環参照(Circular Dependencies): 私の最初の試みは失敗しました。agent.ts が appRouter をインポートし、それが agentRouter をインポートしていたため、循環参照が発生したのです。解決策は? ツールに必要なルーターだけを持つ一時的なルーターをインラインで作成することでした。
ツールのレスポンス抽出: LangChain v1.2でレスポンスのフォーマットが変更されました。結果は result.output ではなく result.messages[result.messages.length - 1].content に入るようになりました。これに気付くのに1時間かかりました。
型安全性(Type Safety): ツールの func パラメータには明示的な型付けが必要です。単に分割代入(destructure)することはできません。まず input をキャストする必要があります。TypeScript はここでは助けてくれません。
自分でセットアップするには
実際に必要なものは以下の通りです:
- 依存関係のインストール:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- 環境変数:
POSTGRES_URL="your-database-url" # Vercel Postgres, Supabase, またはローカルのPostgreSQLを試してください
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # https://aistudio.google.com/app/apikey から取得
- データベースのセットアップ:
pnpm db:push # スキーマからテーブルを作成
- 構築開始:
- データベーススキーマを定義する
- CRUD操作のためのtRPCプロシージャを作成する
- それらのプロシージャをラップするLangChainツールを構築する
- ツールを使ってエージェントを作成する
- フロントエンドに接続する
もしやり直すなら(改善点)
もし明日、最初からやり直すとしたら:
少ないツールから始める。私は最初に7つのツールを作りました。まずは3〜4個の主要なツールに絞るべきです。それらを完璧に動作させてから拡張しましょう。
ツールを独立してテストする。エージェントが完成するまでツールのテストを待ってはいけません。まずはテストデータを使って直接ツールを呼び出してみてください。
ツールの使用状況を監視する。エージェントがどのツールをなぜ呼び出したかを確認するためにログを追加しました。これにより、ツールの説明文(description)に改善が必要なことが分かりました。
ストリーミングを使用する。現状では、ユーザーは完全なレスポンスが返ってくるまで待たされます。ストリーミングを使えば、処理時間は同じでも体感速度は速くなります。
現実的な話(Reality Check)
AIエージェントの構築は魔法ではありませんが、些細なことでもありません。実際のAI部分よりも、以下のことに多くの時間を費やすことになるでしょう:
- ツール設計(各ツールは何をすべきか?)
- プロンプトエンジニアリング(どうすればエージェントが正しく振る舞うか?)
- エラー処理(データベースがダウンしたら? LLMがハルシネーションを起こしたら?)
- 型安全性(動的なLLMレスポンスに対してTypeScriptを満足させること)
実際に試してみる
このチュートリアルのコードは本物です。この記事を書きながら構築しました。以下のようなことができます:
- テスト:「モックユーザーを3人作成して」
- 試行:「ユーザー1のためにブログ記事を2つ作成して」
- 質問:「現在ユーザーは何人いますか?」
エージェントは、どのツールを呼び出すべきかを判断し、実行し、会話形式で応答することで、これらすべてを処理します。
次のステップ
これは単なる基礎に過ぎません。ここからさらに以下のようなことができます:
- 認証の追加(誰が何を作成できるか?)
- ストリーミングレスポンスの実装
- より複雑なツールの追加(検索、分析、外部連携)
- フィードバックループの構築(ツール呼び出しは成功したか?)
- レート制限の追加(ユーザーに1万件の記事を作成させないように)
しかし、まずはシンプルに始めましょう。10個の平凡なツールを追加する前に、1つのツールをうまく機能させてください。
最高なのは、このパターン(ツール + LLM + メモリ)さえ理解すれば、どんなエージェントでも作れるということです。データベース管理、カスタマーサポート、コンテンツ生成など、何でもありです。
難しいのはコードではありません。実際の問題を解決するツールを設計することなのです。
リソース:
- 完全なソースコード: github.com/giftedunicorn/my-ai-agent
- Create T3 Turbo で構築
- LangChain ドキュメント: js.langchain.com
- Gemini APIキーの取得: aistudio.google.com
シェア

執筆者 Feng Liu
shenjian8628@gmail.com