The Multi-Agent Architecture Shift: What 70 Days of Running an AI Agent Fleet Actually Taught Me
Most multi-agent architecture tutorials stop at "chain some tool calls." Here's what 70 days of running an actual agent fleet taught about what really matters.
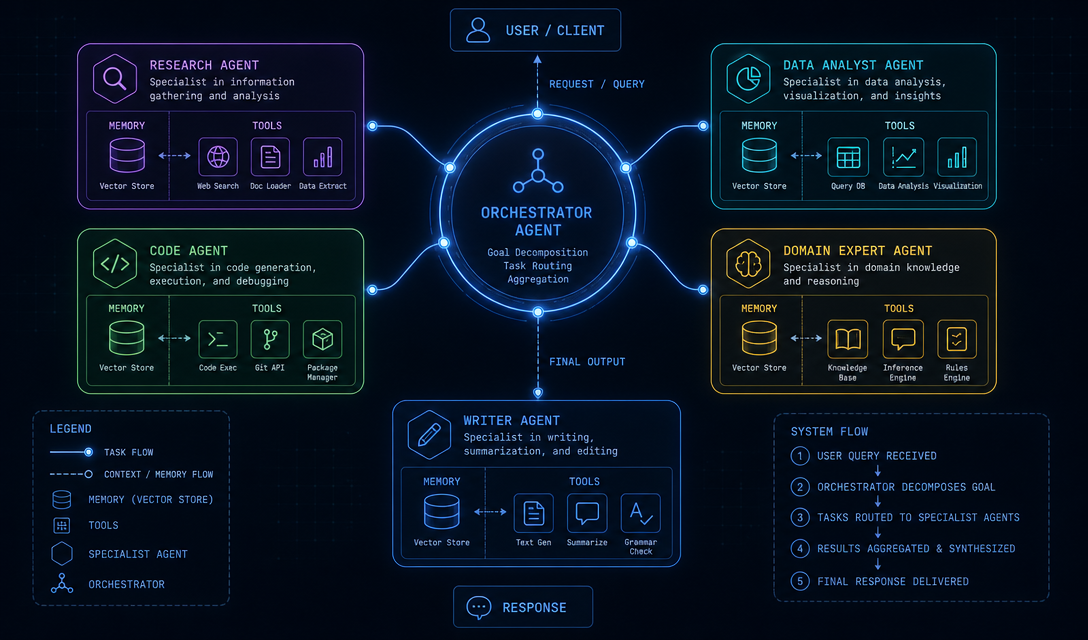
Anthropicrecently called it the shift from the "conversation era" to the "execution era." That's a useful frame — but it obscures something more specific and actionable: the jump from a single AI agent to a coordinated multi-agent system is not a matter of adding more agents. It's a fundamentally different AI agent architecture problem.
I've been thinking about this a lot after reading through both Anthropic's 2026 Agentic Coding Trends Report and a detailed post-mortem from a founder who ran a multi-agent delegation system for 70 days straight. Between those two sources and my own work building on top of Claude, I want to break down what actually changes when you make the leap — and what most tutorials get completely wrong about multi-agent design.
Why Single Agents Break at Scale
The failure mode of a single-agent system is something Anthropic calls "context saturation." It sounds technical, but the practical reality is simple: the more you ask one agent to do, the worse it performs. Memory dilutes. Latency grows. Tool overload kicks in.
If you've ever watched a Claude Code session drift — where the model starts making decisions that contradict things it said 40 messages ago — you've seen context saturation in action. The agent hasn't "forgotten." It's just trying to hold too much state at once and trading off precision for breadth.
Multi-agent architectures solve this by doing what any good engineering system does: separation of concerns. Instead of one agent that knows everything, you have a lead orchestrator that delegates to specialists. Each specialist runs in a bounded context with a clear job. The orchestrator doesn't write code — it breaks work into pieces and manages state across the system.
The Architecture Layer Nobody Talks About
Here's what surprises most developers building their first multi-agent system: the hard part isn't the agents. It's the six layers underneath them.
Anthropicoutlines what they call the "Agent-Native stack":
- Compute — where agents run
- Runtime/Orchestration — how agents are invoked and coordinated
- Memory/Context — how state is stored and retrieved across sessions
- Governance/Identity — who is allowed to do what (this gets complicated fast)
- Economic Coordination — how agent actions are priced and constrained
- Human Interfaces — where humans plug in to review, override, or approve
Most tutorials stop at layers 1 and 2. They show you how to call Claude from Python and chain a few tool calls. That's not a multi-agent system — that's a loop.
The layer that I've found most underappreciated in practice is Memory/Context. This is where the real latency and cost problems live. If your agents don't have a coherent memory strategy, they either re-derive the same context on every call (expensive) or carry stale context that leads them wrong (dangerous).
The layer that's newest and most interesting is Economic Coordination. As agents become more autonomous, you need hard constraints on what they can spend — not just token budgets, but real-world resource limits. One founder who ran 14 SaaS products on AI agents described this exactly: his agents reported a 40% increase in conversion value because they couldn't distinguish between micro-conversions worth fractions of a cent and actual revenue. He had to implement hard rules preventing agents from touching ad budgets at all.
That's not an edge case. That's what happens when you skip the governance layer.
Brief Quality Beats Model Quality
This is the counterintuitive finding from the 70-day multi-agent experiment, and it matches everything I've seen building on top of Claude.
The experiment ran a decision-layer agent on Opus with specialist agents delegated by role. The expectation was that model quality would be the primary lever. It wasn't. Brief quality was.
Specifically: agents given "execute-only" briefs — where acceptance criteria were treated as ground truth — produced consistently worse results than agents given briefs that also included validation criteria. The execute-only agent would complete the task as specified, even when the specification was subtly wrong. The agent with validation criteria would flag the discrepancy.
This changes how you should think about multi-agent AI agent architecture. The prompt isn't just an instruction — it's the quality gate. Writing a good brief for an AI agent is closer to writing a good engineering spec than writing a good chat message.
The Adversarial Design Pattern
Another finding from the same experiment: system-prompting agents to be adversarial improved reliability. Not adversarial toward users — adversarial toward each other.
The intuition: agents that are designed to agree tend to amplify errors. If your orchestrator proposes a flawed plan and all your specialists are optimized to execute, nobody catches the flaw. But if one specialist is explicitly prompted to find holes in the plan — to be antisycophantic — the system becomes self-correcting.
A practical version of this: run two agents with identical tasks but different framings ("how would you do this" vs. "what's wrong with the conventional approach"). Use a third agent to consolidate and flag disagreements. Disagreement is a cheap signal that the premise is shaky.
This is borrowed from red team / blue team security thinking. It works for the same reason: you can't stress-test a system from inside the same assumptions that built it.
What This Means for Solo Builders
If you're a solo founder building AI agent workflows, the 2026 landscape gives you infrastructure that wasn't available a year ago. Claude Managed Agents now supports stateful sessions with persistent filesystems, multiagent orchestration where a lead agent breaks work into specialist tasks, and backgrounded sessions you can check on from mobile.
But the infrastructure existing doesn't mean the hard design problems are solved. The founders who are actually making multi-agent systems work are the ones who've figured out:
- Context management: How do your agents know what they need to know without drowning in everything?
- Brief discipline: Are your agent instructions written with validation criteria, not just acceptance criteria?
- Failure modes: What happens when an agent is confidently wrong? Does the system catch it?
The model is almost never the bottleneck. The architecture around it is.
Practical Starting Point
If you're implementing a multi-agent AI agent architecture for the first time, I'd suggest starting with three agents rather than one:
- A Planner agent that breaks work into subtasks and writes briefs
- An Executor agent that treats the brief as its only ground truth
- A Validator agent that reviews the output against the original goal — not the brief
The Validator-Executor separation is the critical piece. The Executor's job is to follow instructions. The Validator's job is to ask whether the instructions were right in the first place. That's the adversarial dynamic, built into the minimum viable architecture.
Once you have that working, add memory. Then add governance. Don't add more agents until you've solved the layers underneath.
The execution era is real. But execution without architecture is just faster failure.
Building multi-agent systems and want to compare notes? I share what's working (and what isn't) regularly here and on X.
Compartir esto

Escrito por Feng Liu
shenjian8628@gmail.com