Del 2: Byg din første AI-agent: En praktisk guide med LangChain
De fleste tutorials om AI-agenter springer de besværlige detaljer over. Her viser jeg, hvordan jeg byggede en fungerende agent med LangChain, tRPC og PostgreSQL – inklusiv de fejl, jeg begik undervejs.
Hypen omkring AI-agenter er reel. Alle taler om autonome systemer, der kan tænke, planlægge og udføre opgaver. Men her er det, ingen fortæller dig: de fleste tutorials viser dig "the happy path" og springer over de dele, hvor tingene går i stykker.
I sidste uge brugte jeg to dage på at bygge en AI-agent helt fra bunden. Ikke et legetøjseksempel – en rigtig en, der administrerer en blogplatform, opretter brugere, skriver indlæg og faktisk virker. Jeg vil vise dig præcis, hvordan jeg gjorde det, inklusive de dele, der ikke virkede første gang.
Fuld kildekode: github.com/giftedunicorn/my-ai-agent
Hvad vi faktisk bygger
Glem de abstrakte eksempler. Vi bygger en agent, der:
- Opretter og administrerer brugere i en PostgreSQL-database
- Genererer blogindlæg på opfordring
- Svarer i et naturligt sprog mens den bruger værktøjer
- Bevarer samtalehistorik
- Faktisk deployer (ikke bare localhost-demoer)
Vores stack: Next.js, tRPC, Drizzle ORM, LangChain og Google's Gemini. Ikke fordi det er trendy – men fordi det er typesikkert, hurtigt og faktisk virker i produktion.
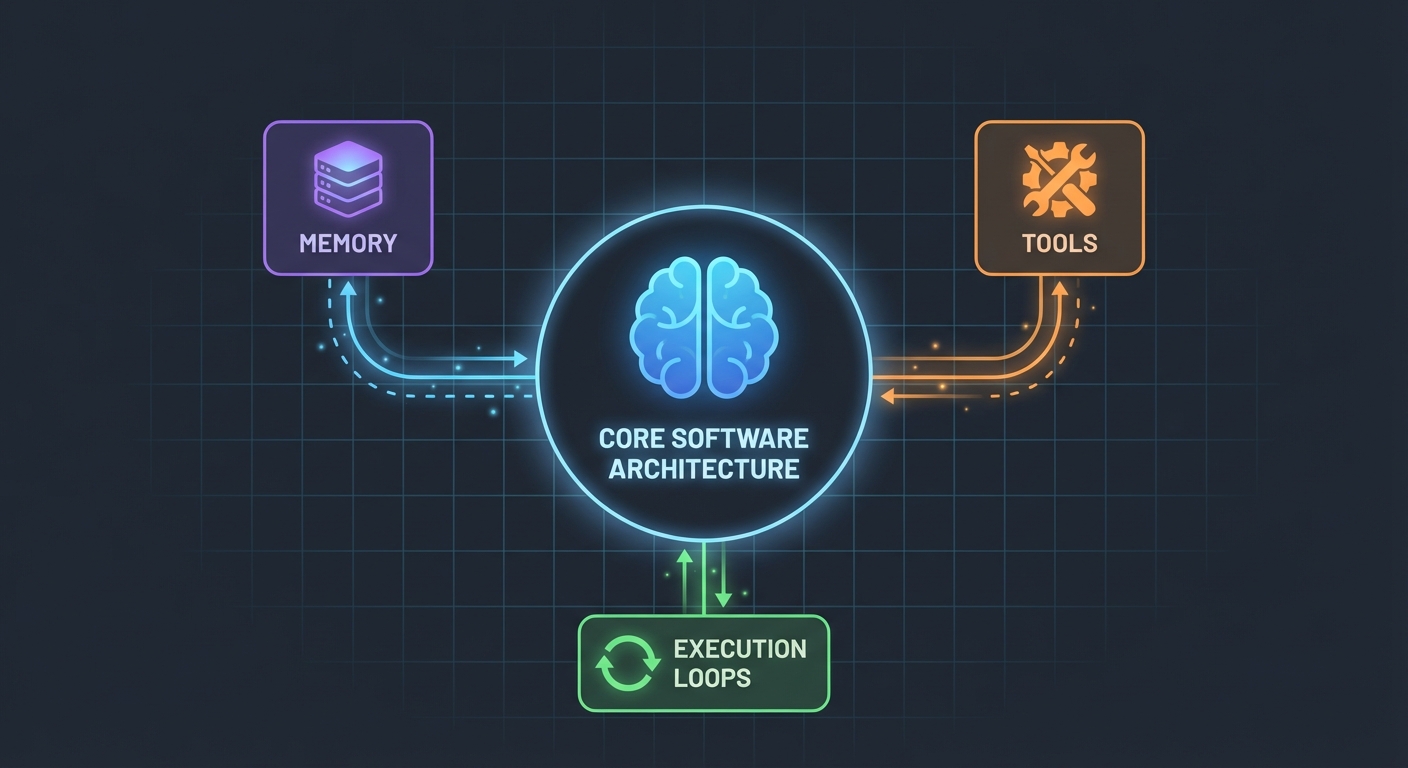
Arkitekturen (Simplere end du tror)
Her er, hvad der overraskede mig: AI-agenter er ikke så komplicerede. I deres kerne er de bare:
- En LLM, der kan kalde funktioner
- Et sæt værktøjer, som LLM'en kan bruge
- Et loop, der eksekverer disse værktøjer
- Hukommelse til at bevare kontekst
Det er det. Kompleksiteten opstår ved at få disse dele til at arbejde pålideligt sammen.
Databaseskemaet
Først fundamentet. Vi har brug for tabeller til brugere, indlæg og beskeder:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
Ikke noget fancy. Bare rene, relationelle data med PostgreSQL. Message-tabellen gemmer samtalehistorikken – hvilket er afgørende for at bevare konteksten mellem forespørgsler.
Opbygning af værktøjerne (Hvor magien sker)
Det er her, de fleste tutorials bliver vage. "Bare lav nogle værktøjer," siger de. Lad mig vise dig, hvordan det faktisk ser ud.
Værktøjer er funktioner, din AI kan kalde. Med LangChains DynamicStructuredTool definerer du:
- Hvad værktøjet gør (beskrivelse)
- Hvilke inputs det behøver (schema med Zod)
- Hvad det faktisk eksekverer (funktion)
Her er værktøjet til at oprette brugere:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
Beskrivelsen betyder mere, end du tror. LLM'en bruger den til at beslutte, hvornår dette værktøj skal kaldes. Vær specifik omkring, hvornår det skal bruges.
Returværdien? Det er det, LLM'en ser. Jeg returnerer struktureret tekst med alle relevante detaljer – ID'er, navne, bekræftelse. Dette hjælper LLM'en med at give bedre svar til brugerne.
Agenten: Samling af det hele
Her bliver det interessant. Den nye LangChain API (v1.2+) har forenklet alt:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
Det er det hele. Ingen ChatPromptTemplate, ingen AgentExecutor, ingen komplekse chains. Bare createAgent og invoke.
System-prompten (Din agents personlighed)
Det er her, du lærer din agent, hvordan den skal opføre sig:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
Jeg lærte dette på den hårde måde: vær eksplicit. Fortæl agenten præcis, hvad den skal gøre, hvordan den skal svare, og hvilke detaljer den skal inkludere. Vage prompts fører til vag adfærd.
Håndtering af samtalehistorik
De fleste eksempler springer dette over, men det er kritisk for en god brugeroplevelse. Her er, hvordan jeg håndterer det:
// Hent de sidste 10 beskeder fra databasen
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Konverter til LangChain-format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
Simpelt, men effektivt. Agenten husker nu de sidste 10 udvekslinger. Nok til kontekst, men ikke så meget at den bliver forvirret eller dyr i drift.
De rodede dele (Hvad der faktisk gik galt)
Cirkulære afhængigheder: Mit første forsøg fejlede, fordi agent.ts importerede appRouter, som importerede agentRouter, hvilket skabte en cirkulær afhængighed. Løsningen? Opret en midlertidig router inline med kun de routere, du har brug for til værktøjerne.
Udtrækning af værktøjs-respons: LangChains responsformat ændrede sig i v1.2. Resultatet ligger nu i result.messages[result.messages.length - 1].content, ikke result.output. Det tog mig en time at regne ud.
Typesikkerhed: Værktøjets func-parameter kræver eksplicit typing. Du kan ikke bare destrukturere – du er nødt til at caste input først. TypeScript hjælper dig ikke her.
Opsætning af din egen
Her er, hvad du faktisk har brug for:
- Installer afhængigheder:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- Miljøvariabler:
POSTGRES_URL="your-database-url" # Prøv Vercel Postgres, Supabase eller lokal PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Hent fra https://aistudio.google.com/app/apikey
- Databaseopsætning:
pnpm db:push # Opretter tabeller fra schema
- Begynd at bygge:
- Definer dit databaseskema
- Opret tRPC-procedurer til CRUD-operationer
- Byg LangChain-værktøjer, der wrapper disse procedurer
- Opret agenten med dine værktøjer
- Forbind det hele til din frontend
Hvad jeg ville gøre anderledes
Hvis jeg skulle starte forfra i morgen:
Start med færre værktøjer. Jeg byggede 7 værktøjer til at starte med. Hold dig til 3-4 kerneværktøjer først. Få dem til at virke perfekt, og udvid derefter.
Test værktøjer uafhængigt. Vent ikke til agenten er bygget med at teste dine værktøjer. Kald dem direkte med testdata først.
Overvåg brug af værktøjer. Jeg tilføjede logging for at se, hvilke værktøjer agenten kalder og hvorfor. Dette afslørede, at mine værktøjsbeskrivelser trængte til forbedring.
Brug streaming. Lige nu venter brugerne på det fulde svar. Streaming ville få det til at føles hurtigere, selvom det tager samme tid.
Realitetstjekket
At bygge AI-agenter er ikke magi, men det er heller ikke trivielt. Du kommer til at bruge mere tid på:
- Værktøjsdesign (hvad skal hvert værktøj gøre?)
- Prompt engineering (hvordan får jeg agenten til at opføre sig korrekt?)
- Fejlhåndtering (hvad hvis databasen er nede? hvad hvis LLM'en hallucinerer?)
- Typesikkerhed (at gøre TypeScript glad for dynamiske LLM-svar)
End på selve AI-delen.
Prøv det selv
Koden til denne tutorial er ægte – jeg byggede den, mens jeg skrev dette. Du kan:
- Teste den med: "create 3 mock users"
- Prøve: "create 2 blog posts for user 1"
- Spørge: "how many users do we have?"
Agenten håndterer alle disse ved at beslutte, hvilke værktøjer den skal kalde, eksekvere dem og svare i et naturligt sprog.
Hvad er det næste
Dette er kun fundamentet. Herfra kunne du:
- Tilføje autentificering (hvem kan oprette hvad?)
- Implementere streaming af svar
- Tilføje mere komplekse værktøjer (søgning, analytics, integrationer)
- Bygge et feedback-loop (lykkedes værktøjskaldet?)
- Tilføje rate limiting (lad ikke brugere oprette 10.000 indlæg)
Men start simpelt. Få ét værktøj til at virke godt, før du tilføjer ti middelmådige.
Det bedste ved det hele? Når du først forstår dette mønster – værktøjer + LLM + hukommelse – kan du bygge agenter til hvad som helst. Databaseadministration, kundesupport, indholdsgenerering, whatever.
Den svære del er ikke koden. Det er at designe værktøjer, der faktisk løser reelle problemer.
Ressourcer:
- Fuld kildekode: github.com/giftedunicorn/my-ai-agent
- Bygget med Create T3 Turbo
- LangChain Docs: js.langchain.com
- Hent Gemini API-nøgle: aistudio.google.com
Del dette

Skrevet af Feng Liu
shenjian8628@gmail.com