الجزء 2: بناء أول وكيل ذكاء اصطناعي: دليل عملي باستخدام LangChain
تتجاهل معظم شروحات الـ AI Agents الجوانب الفوضوية والمعقدة. إليكم تجربتي في بناء Agent يعمل بكفاءة باستخدام LangChain و tRPC و PostgreSQL - بما في ذلك الأخطاء التي ارتكبتها طوال الرحلة.
Title: بناء وكيل ذكاء اصطناعي حقيقي: ما تتجاهله الشروحات التعليمية Excerpt: الجميع يتحدث عن وكلاء الذكاء الاصطناعي، لكن معظم الشروحات تريك السيناريو المثالي فقط. إليك كيف بنيت وكيلاً حقيقياً يدير منصة تدوين، بما في ذلك الأخطاء والمشاكل التي واجهتها وكيفية حلها.
Content: الضجة حول وكلاء الذكاء الاصطناعي (AI Agents) حقيقية. الكل يتحدث عن أنظمة مستقلة يمكنها التفكير، التخطيط، وتنفيذ المهام. لكن إليك ما لا يخبرك به أحد: معظم الشروحات التعليمية تريك "المسار السعيد" (happy path) وتتجاهل اللحظات التي تنهار فيها الأمور وتتوقف عن العمل.
في الأسبوع الماضي، قضيت يومين في بناء وكيل ذكاء اصطناعي من الصفر. ليس مجرد مثال بسيط للعب - بل وكيل حقيقي يدير منصة تدوين، ينشئ المستخدمين، يكتب المقالات، ويعمل بالفعل. سأريكم بالضبط كيف فعلت ذلك، بما في ذلك الأجزاء التي لم تنجح من المحاولة الأولى.
الكود الكامل: github.com/giftedunicorn/my-ai-agent
ما الذي نبنيه فعلياً؟
دعك من الأمثلة النظرية المجردة. نحن بصدد بناء وكيل يقوم بـ:
- إنشاء وإدارة المستخدمين في قاعدة بيانات PostgreSQL
- توليد مقالات للمدونة عند الطلب
- الرد بأسلوب محادثة طبيعي أثناء استخدام الأدوات
- الاحتفاظ بسجل المحادثة (History)
- العمل فعلياً عند النشر (Deploy) وليس فقط على السيرفر المحلي (localhost)
التقنيات المستخدمة (The Stack): Next.js، tRPC، Drizzle ORM، LangChain، و Google's Gemini. ليس لأنها "تريند" أو عصرية - بل لأنها آمنة من حيث النوع (type-safe)، وسريعة، وتعمل فعلياً في بيئة الإنتاج.
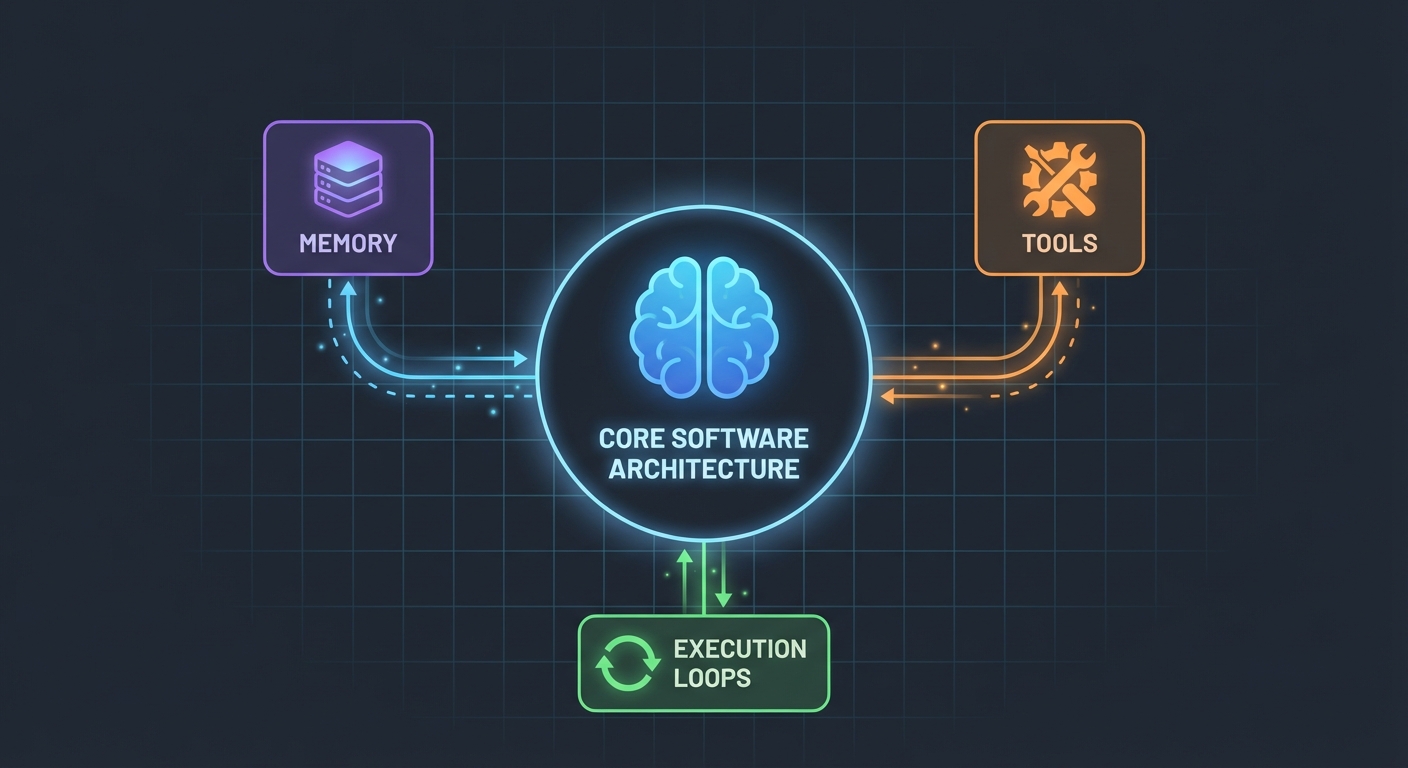
البنية الهندسية (أبسط مما تعتقد)
إليك ما فاجأني: وكلاء الذكاء الاصطناعي ليسوا بتلك الدرجة من التعقيد. في جوهرهم، هم مجرد:
- نموذج لغوي (LLM) يمكنه استدعاء الدوال (Functions)
- مجموعة من الأدوات التي يمكن للنموذج استخدامها
- حلقة تكرار (Loop) تنفذ تلك الأدوات
- ذاكرة للحفاظ على السياق (Context)
هذا كل شيء. التعقيد يأتي من جعل هذه القطع تعمل معاً بشكل موثوق.
مخطط قاعدة البيانات (Database Schema)
أولاً، الأساس. نحتاج إلى جداول للمستخدمين، المقالات، والرسائل:
export const User = pgTable("user", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
name: t.varchar({ length: 255 }).notNull(),
email: t.varchar({ length: 255 }).notNull().unique(),
bio: t.text(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
export const Post = pgTable("post", (t) => ({
id: t.integer().primaryKey().generatedAlwaysAsIdentity(),
userId: t
.integer()
.notNull()
.references(() => User.id, { onDelete: "cascade" }),
title: t.varchar({ length: 500 }).notNull(),
content: t.text().notNull(),
published: t.boolean().default(false).notNull(),
createdAt: t.timestamp().defaultNow().notNull(),
updatedAt: t.timestamp().defaultNow().notNull(),
}));
لا شيء معقد. مجرد بيانات علائقية نظيفة باستخدام PostgreSQL. جدول Message يخزن سجل المحادثة - وهو أمر بالغ الأهمية للحفاظ على السياق بين الطلبات.
بناء الأدوات (حيث يحدث السحر)
هنا تصبح معظم الشروحات غامضة. يقولون لك "فقط أنشئ بعض الأدوات". دعني أريكم كيف يبدو ذلك في الواقع.
الأدوات هي دوال (Functions) يمكن للذكاء الاصطناعي استدعاؤها. باستخدام DynamicStructuredTool من LangChain، أنت تحدد:
- ما تفعله الأداة (الوصف - description)
- المدخلات التي تحتاجها (المخطط باستخدام Zod)
- ما تنفذه الأداة فعلياً (الدالة - function)
إليك أداة إنشاء المستخدمين:
const createUserTool = new DynamicStructuredTool({
name: "create_user",
description:
"Create a new user in the database. Use this when asked to add, create, or register a user.",
schema: z.object({
name: z.string().describe("The user's full name"),
email: z.string().email().describe("The user's email address"),
bio: z.string().optional().describe("Optional biography"),
}),
func: async (input) => {
const { name, email, bio } = input as {
name: string;
email: string;
bio?: string;
};
const user = await caller.user.create({ name, email, bio });
return `Successfully created user: ${user.name} (ID: ${user.id}, Email: ${user.email})`;
},
});
الوصف (description) أهم مما تتخيل. يستخدمه النموذج اللغوي ليقرر متى يستدعي هذه الأداة. كن محدداً جداً حول متى يجب استخدامها.
وماذا عن القيمة المرجعة (return value)؟ هذا ما يراه النموذج اللغوي. أنا أقوم بإرجاع نص مهيكل يحتوي على كل التفاصيل ذات الصلة - المعرفات (IDs)، الأسماء، ورسالة التأكيد. هذا يساعد النموذج على تقديم إجابات أفضل للمستخدمين.
الوكيل: تجميع القطع معاً
هنا يصبح الأمر مثيراً للاهتمام. قامت واجهة برمجة تطبيقات LangChain الجديدة (الإصدار v1.2+) بتبسيط كل شيء:
const agent = createAgent({
model: new ChatGoogleGenerativeAI({
apiKey: process.env.GOOGLE_GENERATIVE_AI_API_KEY,
model: "gemini-2.0-flash-exp",
temperature: 0.7,
}),
tools: [...createUserTools(caller), ...createPostTools(caller)],
systemPrompt: AGENT_SYSTEM_PROMPT,
});
const result = await agent.invoke({
messages: conversationMessages,
});
هذا كل شيء. لا حاجة لـ ChatPromptTemplate، ولا AgentExecutor، ولا سلاسل معقدة. فقط createAgent و invoke.
موجه النظام (شخصية وكيلك)
هنا تقوم بتعليم وكيلك كيف يتصرف:
const AGENT_SYSTEM_PROMPT = `You are an AI assistant that helps manage a blog platform.
You have access to tools for:
- User management (create, read, list, count)
- Post management (create, list)
When users ask you to perform actions:
1. Use the appropriate tools to complete the task
2. Be conversational and friendly
3. Provide clear confirmation with specific details
4. When creating mock data, use realistic names and content
Always confirm successful operations with relevant details.`;
تعلمت هذا بالطريقة الصعبة: كن صريحاً. أخبر الوكيل بالضبط ماذا يفعل، كيف يرد، وما هي التفاصيل التي يجب تضمينها. التعليمات الغامضة تؤدي إلى سلوك غامض.
التعامل مع سجل المحادثة (History)
تتجاهل معظم الأمثلة هذه النقطة، لكنها حاسمة لتجربة مستخدم جيدة. إليك كيف أتعامل معها:
// Get last 10 messages from database
const history = await ctx.db
.select()
.from(Message)
.orderBy(desc(Message.createdAt))
.limit(10);
// Convert to LangChain format
const conversationMessages = [
...history.reverse().map((msg) => ({
role: msg.role === "user" ? "user" : "assistant",
content: msg.content,
})),
{ role: "user", content: input.message },
];
بسيط، لكنه فعال. الوكيل الآن يتذكر آخر 10 تبادلات للحديث. كافٍ للحفاظ على السياق، وليس كثيراً لدرجة أن يجعله مشتتاً أو مكلفاً.
الأجزاء الفوضوية (ما تعطل بالفعل)
الاعتمادات الدائرية (Circular Dependencies): فشلت محاولتي الأولى لأن agent.ts كان يستورد appRouter، الذي بدوره يستورد agentRouter، مما خلق حلقة مفرغة. الحل؟ إنشاء "router" مؤقت ومضمن يحتوي فقط على الـ routers التي تحتاجها للأدوات.
استخراج استجابة الأداة: تغير تنسيق الاستجابة في LangChain v1.2. النتيجة الآن موجودة في result.messages[result.messages.length - 1].content، وليس في result.output. استغرق مني الأمر ساعة لاكتشاف ذلك.
أمان النوع (Type Safety): معامل func في الأداة يحتاج إلى تحديد نوع صريح. لا يمكنك فقط تفكيك الكائن (destructure) - تحتاج إلى تحويل نوع input أولاً. لن يساعدك TypeScript هنا بشكل تلقائي.
إعداد نسختك الخاصة
إليك ما تحتاجه فعلياً:
- تثبيت الاعتمادات:
pnpm add @langchain/core @langchain/google-genai langchain drizzle-orm
- متغيرات البيئة:
POSTGRES_URL="your-database-url" # Try Vercel Postgres, Supabase, or local PostgreSQL
GOOGLE_GENERATIVE_AI_API_KEY="your-gemini-key" # Get from https://aistudio.google.com/app/apikey
- إعداد قاعدة البيانات:
pnpm db:push # Creates tables from schema
- ابدأ البناء:
- حدد مخطط قاعدة البيانات الخاصة بك
- أنشئ إجراءات tRPC لعمليات الـ CRUD
- ابنِ أدوات LangChain التي تغلف تلك الإجراءات
- أنشئ الوكيل باستخدام أدواتك
- اربطه بالواجهة الأمامية (frontend)
ما كنت سأفعله بشكل مختلف
لو بدأت من جديد غداً:
ابدأ بأدوات أقل. قمت ببناء 7 أدوات في البداية. التزم بـ 3-4 أدوات أساسية أولاً. اجعلها تعمل بشكل مثالي، ثم توسع.
اختبر الأدوات بشكل مستقل. لا تنتظر حتى يتم بناء الوكيل لاختبار أدواتك. استدعها مباشرة ببيانات اختبار أولاً.
راقب استخدام الأدوات. أضفت سجلات (logging) لأرى أي الأدوات يستدعيها الوكيل ولماذا. كشف هذا أن أوصاف أدواتي كانت بحاجة إلى تحسين.
استخدم البث (Streaming). حالياً، ينتظر المستخدمون الاستجابة الكاملة. استخدام الـ Streaming سيجعل الأمر يبدو أسرع، حتى لو استغرق نفس الوقت.
فحص الواقع
بناء وكلاء الذكاء الاصطناعي ليس سحراً، لكنه ليس تافهاً أيضاً. ستقضي وقتاً أطول في:
- تصميم الأدوات (ماذا يجب أن تفعل كل أداة؟)
- هندسة الأوامر/Prompt Engineering (كيف أجعل الوكيل يتصرف بشكل صحيح؟)
- معالجة الأخطاء (ماذا لو تعطلت قاعدة البيانات؟ ماذا لو بدأ النموذج بالهلوسة؟)
- أمان النوع (إرضاء TypeScript مع استجابات LLM الديناميكية)
أكثر مما ستقضيه في جزء الذكاء الاصطناعي الفعلي.
جرب بنفسك
الكود الخاص بهذا الشرح حقيقي - قمت ببنائه أثناء كتابة هذا المقال. يمكنك:
- اختباره بـ: "create 3 mock users" (أنشئ 3 مستخدمين وهميين)
- تجربة: "create 2 blog posts for user 1" (أنشئ مقالين للمستخدم رقم 1)
- السؤال: "how many users do we have?" (كم عدد المستخدمين لدينا؟)
يتعامل الوكيل مع كل هذه الطلبات من خلال تحديد الأدوات التي يجب استدعاؤها، وتنفيذها، والرد بأسلوب محادثة.
ماذا بعد
هذا مجرد أساس. من هنا، يمكنك:
- إضافة المصادقة (من يمكنه إنشاء ماذا؟)
- تنفيذ استجابات البث (Streaming responses)
- إضافة أدوات أكثر تعقيداً (بحث، تحليلات، تكاملات)
- بناء حلقة تغذية راجعة (هل نجح استدعاء الأداة؟)
- إضافة تحديد المعدل (Rate limiting) (لا تدع المستخدمين ينشئون 10,000 مقال)
لكن ابدأ ببساطة. اجعل أداة واحدة تعمل بشكل جيد قبل إضافة عشر أدوات متوسطة الجودة.
الجزء الأفضل؟ بمجرد أن تفهم هذا النمط - أدوات + LLM + ذاكرة - يمكنك بناء وكلاء لأي شيء. إدارة قواعد البيانات، دعم العملاء، إنشاء المحتوى، أياً كان.
الجزء الصعب ليس الكود. إنه تصميم أدوات تحل مشاكل حقيقية بالفعل.
المصادر:
- الكود المصدري الكامل: github.com/giftedunicorn/my-ai-agent
- تم البناء باستخدام Create T3 Turbo
- وثائق LangChain: js.langchain.com
- احصل على مفتاح Gemini API: aistudio.google.com
شارك هذا

بقلم Feng Liu
shenjian8628@gmail.com